
正则表达式快速入门
正则表达式快速入门
学习源视频:奇乐编程学院-[Bilibili]
Note:XLY23333-[Blog]
NoteBy:Typora[Markdown] + $\rm\LaTeX$ Themes by:Keldos-Li-[Github]
限定符 [Quantifiers]
单个字符的限定
| $\quad$限定符$\quad$ | Description | $\quad$Eg$\quad$ | Egmeans |
|---|---|---|---|
? |
?前字符出现0或1次(?前字符可有可无) | used? |
查找所有use和used |
* |
*前字符出现0或多次(*前字符可有多次可无) | ab?c |
可查找abc,ac,abbbc等 |
+ |
+前字符出现1或多次(+前字符可有一次或多次) | ab+c |
可查找abc,abbbc等 |
{<num>} |
指定{…}前字符出现次数为<num>次 |
ab{2}c |
可查找abbc等 |
{<min>,<max>} |
指定{…}前字符出现次数范围,可以缺省max值 |
ab{3,}c |
可查找abbbbc,abbbc等 |
多个字符的限定
可以使用()将多个字符括起,随后操作同上方的单个字符限定
Eg:a(bc){1,2}d可以搜索 ‘abcd’ 和 ‘abcbcd’
或运算符 [OR Operation]
同时匹配所有出现的情况,只要有就匹配
Code: (<word1>|<words2>|<words3>|...)
使用()将或运算内容括起,用|将内容隔开,则括号中所有的内容执行或运算,均可以被查找到
Eg:a (cat|dog)可以搜索 ‘a cat’ 和 ‘a dog’ [注意:a后方的空格也算作检索内容]
字符类 [Character Classes]
匹配由指定字符所构成的内容,无需完全匹配,拥有其中之一即可
Code: [<char1><char2>...]并列查找由他们构成的内容
[<char1>-<char2>] 定义查找范围<char1>-<char2>
[^<char>]查找除了方括号的其他内容
Eg: [^\nA-Za-z]+ 查找所有的数字(非换行符,非大写字母,非小写字母)
元字符 [Meta-Characters]
| $\quad$Meta-Char$\quad$ | $\quad$Description$\quad$ |
|---|---|
\d |
数字字符 |
\w |
单词字符(英文字母+数字+下划线) |
\s |
空白符(TAB+换行符) |
\D |
非数字字符 |
\W |
非单词字符 |
\S |
非空白符 |
. |
任意字符(不包含换行符) |
^<char> |
匹配行首的<char> |
<char>$ |
匹配行尾的<char> |
\b<chars>\b |
规定该位置为单词边界,防止对超量的截取匹配 |
\B<chars>\B |
规定该位置为非单词边界 |
如果要使用.则可以通过转义后的\.进行匹配
贪婪与懒惰匹配 [Greedy vs Lazy Match]
假设对一下的html内容,需要匹配<center>和</center>>
1 | <center>TEXT</center> |
如果使用<.+>,由于>和<同样属于.,所以将匹配整行的全部代码
可以将代码更改为<.+?>由贪婪模式匹配为懒惰匹配,从而精确匹配
也可以在不切换模式的情况下,改用<[^<>]+>去掉可能出现的>和<查找
实战练习
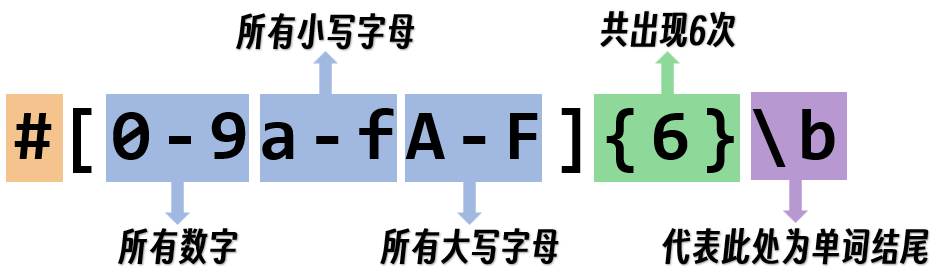
匹配16进制的颜色值
颜色值#开头,为十六进制(由0~9,a~f,A~F构成),共6位字符
IPv4 地址匹配
IPv4由四段数字组成,中间由符号.隔开,且数字的范围为0~255


评论
