
数模M01-评价模型
评价模型
一、层次分析法 AHP
学习源Video:Bilibili-ln异教徒 AHP
作用:层次分析法用来进行决策,求指标的权重
模型建立步骤:
建立层次结构
- 将决策问题分为三个部分:目标层、准则层和指标层/方案层
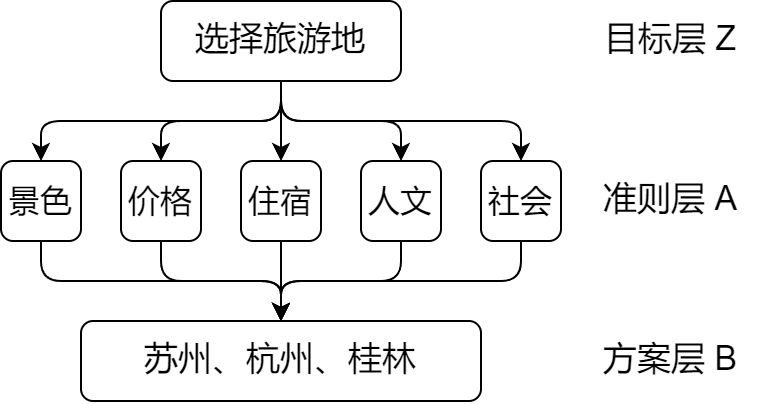
对准则层构建判断矩阵
判断矩阵为两两指标重要性的判断,一般判别矩阵构造如下:
九级标度法表格
| 标度 | 含义 |
| ———————— | ————————————————————- |
| 1 | i和j具有相同的重要性(Eg:主对角线元素) |
| 3 | i比j稍微重要 |
| 5 | i比j明显重要 |
| 7 | i比j强烈重要 |
| 9 | i比j极端重要 |
| 2、4、6、8 | 上述标度的中间量 |
| $\frac{1}{标度}$ | 矩阵下三角对称位置的值 |一致性检验(特征根法)
在通过主观想法确定两个属性之间的重要性差距标度时,可能出现不一致的情况,需要用一致性检验对所得的判断矩阵进行一致性的检验,确定所得的判断矩阵能够使用
一致性的例子:A~12~=2, A~13~=2,那么说明1 对 2和3 的重要程度相同,可以推出2和3的重要程度相同,
即A~23~ = A~32~ =1,如果该值不为1则说明其不一致。
用对应于A的最大特征根(记为$\lambda$)的特征向量(归一化后)作为权向量$w$,即$w$满足
当 $\lambda = n$ 时,该判断矩阵为一致阵,且任何判断矩阵的最大特征根 $\lambda\ge n$ 。因此,当最大特征根比 $n$ 大得多时,该判断矩阵的不一致程度越严重,所以可以用 $\lambda - n$ 的数值来衡量判断矩阵的不一致程度,并将
作为一致性指标,当$CI=0$时判断矩阵为一致阵,并引入随机一致性指标$RI$,$RI$数值如下:
| $n$ | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|
| $RI$ | 0.58 | 0.9 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 |
将它的一致性指标$CI$与同阶(指$n$相同)的随机一致性指标$RI$之比称为一致性比率$CR$,当
时,认为该判断矩阵的不一致程度在容许范围之内,可以用其特征向量作为权向量。最终得到每个指标的权重结果。
- 方法一:使用MATLAB的
eig()方法直接求得特征根 $v$和特征向量$d$,随后通过求取特征向量和特征值的所在列,计算w = v(:,loc)/sum(v(:,loc));得到转为行向量,即权向量res_A。
- 方法一:使用MATLAB的
Matlab-ModelCode
1 | clear |
- 方法二:算术平均法求权重
将判断矩阵按照列归一化$\to$将归一化的结果按行求和$\to$每个元素除以n
- 对指标层/方案层的内容构建
- 每一个准则层性质中 多个指标间的判断矩阵并进行AHP(多个准则,每个准则指向多个指标)
- 每一个准则层性质的 每个方案间的判断矩阵并进行AHP(多个准则,多个主责指向多个方案)
- 将准则层/方案层的每一个准则性质的$w$转成行向量
- 准则层的所有值$w$值构成权向量res_B
- 方案层纵向拼接,所得的即为方案曾的权矩阵res_B,
- 计算最终得分/综合权重
- 指标:res_A(指标层集的大类准则)$\times$res_B所得结果
- 方案:res_A$\times$res_B得到综合权重res_Z
二、熵权法 EWM
学习源Video:Bilibili-ln异教徒 EWM
数据的归一化处理
由于各项指标计量单位并不统一,因此在计算综合权重前先要对它进行标准化处理,即把指标的绝对值转化为相对值,并令 $x{\small ij} = |x{\small ij}|$ ,从而解决各项不同质指标的同质化问题。
方法一:
由于正向指标和负向指标数值代表的含义不同(正向指标数值越高越好,负向指标数值越低越好),因此对于高低需求指标应当采取不同的算法进行数据标准化处理,具体处理方法为 :
对于正向指标:
对于负向指标:
通常会采用一些稍微小一点的值来代替 0 和 1,以便更好地保留原始数据的分布特征。
且直接使用 0 和 1 作为归一化后的极值,可能会导致数据过于集中在边界附近,失去了部分信息。
1 | % Matlab的归一化自定义函数 # Gy.m |
方法二:Python scikit-learn MinMaxScaler
1
2
3
4
5
6
7
8
9
10
11
12
13# 数据归一化(sklearn)
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = [[1,2,3],
[4,5,6],
[7,8,9],]
# 如果data为单列则需添加.values.reshape(-1,1)
print('data:',data[:5]) # 展示前五个数据
MM_Scaler = MinMaxScaler(feature_range=(0,1)) # 默认缩放范围(0,1)
MMres = MM_Scaler.fit_transform(data)
print('MMres:',np.round(MMres[:5,],2)) # 展示前五个数据,保留3位小数
计算第$j$项指标下第$i$方案指标值的比重$p_{ij}$
计算第$j$项指标的熵值$e_j$
其中$k=\dfrac{1}{\ln(n)}$,满足$e_j\ge 0$
计算信息熵冗余度$g_{j}$
计算各项指标权重$w_j$
- 计算综合评分$S_i$
1 | clear |

